本文介绍了一下8b/10b 编码, 主要是从定性的角度来介绍。因为对于我们来说,读取翻译物理信号是逻辑分析仪的工作。
8b/10b是一种广泛应用于高速数据传输领域的线路编码技术,其核心是将 8 位二进制数据(1 字节)映射为 10 位二进制符号后再传输,通过 “增加冗余”解决高速传输中的直流分量偏移、时钟同步丢失等关键问题,常见于 PCI Express、SATA、以太网(部分速率)等接口标准。
这种编码的目的是:
- 在数据中嵌入时钟
8b/10b编码确保数据流中具有足够的边沿让接收端恢复时钟,从而不再需要分配时钟(传输过程不需要通用参考时钟,与之对比的是 SPI 总线,数据线必须在时钟线的帮助下才能得到期望的数据),让传输实现更高的速率(串行)。避免了并行总线的一些缺点,比如飞行时间的限制,时钟偏斜的影响。同样避免了分配高频时钟可能带来的EMI和布线困难的影响。
- 保持DC平衡
以PCIe为例,链路使用AC耦合,链路中放置电容,当频率越高,阻抗越低,反之频率越低,阻抗越高,当码型的0和1交替频繁,那么信号很容易传输过去,但如果出现连续的0或者1,意味着频率降低,可能无法识别0和1。
高速串行总线通常会使用AC耦合电容,而通过编码技术使得DC平衡的原理可以从电容“隔直流、通交流”的角度理解。 如下图所示,DC平衡时,位流中的1和0交替出现,可认为是交流信号,可以顺利的通过电容;DC不平衡时,位流中出现多个连续的1或者0,可认为该时间段内的信号是直流,通过电容时会因为放电导致传输后的编码错误。高速串行总线采用编码技术的目的是平衡位流中的1和0,从而达到DC平衡。大多数串行电路都是ac coupling,就是会在tx端有串电容。电容是隔直通交的,如果不做dc balance,会把直流信号滤除,信号会畸变。但并不是所有的串行电路标准都是ac coupling,比如HDMI就是dc coupling,也就是说HDMI标准电气编码并不是dc balance的。
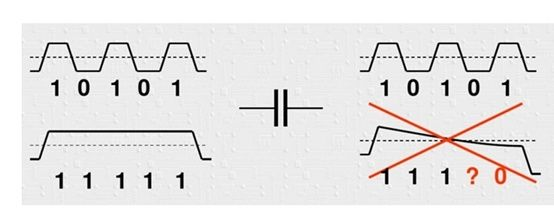
- 加强错误检测
8b/10b编码方案同样加强了错误检测机制,8bit数据有256个编码,而10bit数据有1024个编码,如果1对1进行映射,那么这1024个编码中只需要找出256个编码来对应原始的8bit数据。由于数据的极性偏差要变化来保持DC平衡,所以一些数据映射到10位数据是存在两个数值的,即一个8位数据对应2个10bit的编码后值,分别为为正极性偏差和负极性偏差(无偏差也映射2个),那么数据应该映射了512个编码,即使加上控制符号编码,这个数字也是远小于1024个编码的,那么哪些不被映射的数据,就属于非法字符,接收端也可以依靠判断数据是否在合法来检测错误。
总之,这种编码对于高速信号有很大好处,所以很多高速通讯使用这种编码方式。
这种编码的设计目标是:让最后生成的编码达到 0 和 1 数量相同,并且不会出现超过5个的连续 0 或者 1。
这里介绍一下对于一个数值如何进行编码
1.将需要编码的 8Bit拆分为高 5 Bits 和 低3 Bits,前者是用 EDCBA 表示,后者用 HGF 表示。最后编码后的结果可以记为 Dx.y 或者 Kx.y。 其中的 x就是EDCBA的十进制值(0-31),y是HGF 的十进制值(0-7)。
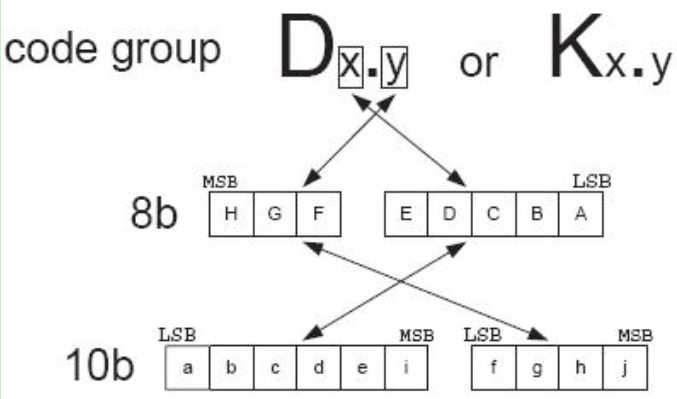
2. 对高5Bit 的编码
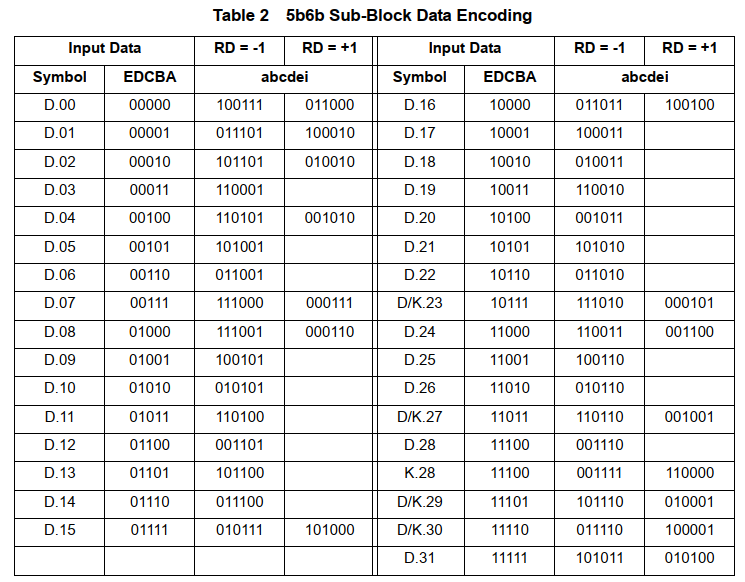
5 Bits变成 6Bits需要在最高位插入一个 bit, 就是说 EDCBA变成 iEDCBA。插入的结果可能是0 也可能是1,于是有下面的表格。可以看到编码后的数字有三种情况:0 和 1 一样多,0比1多2个,0比1少两个。RD:Running Disparity 直译“运行不一致性”,也翻译成“极性偏差”,RD是对编码后的数据流Disparity的一个统计,+1用来表示1比0多,-1用来表示0比1多,-1是它的初始化状态,编码中“1”和“0”数量相等的码字称为“完美平衡码”。图片种会出现 D和K 使用相同的编码情况,比如 D/K 23 27 29 30,但是我猜测在实际使用中不会使用和D定义相同的K值,比如,不会出现 K.23.0 这种,因为会导致通讯时无法分发送的是 D.23.0 还是 K.23.0。
3.对 低3位的编码
3 Bits变成 4Bits同样需要在最高位插入一个 bit, 就是说 HGF变成 jHGF。同样也是使用原始值查表。同样的编码后的结果要么 0 1 一样多,要么0比1多2个,要么0比1少两个。
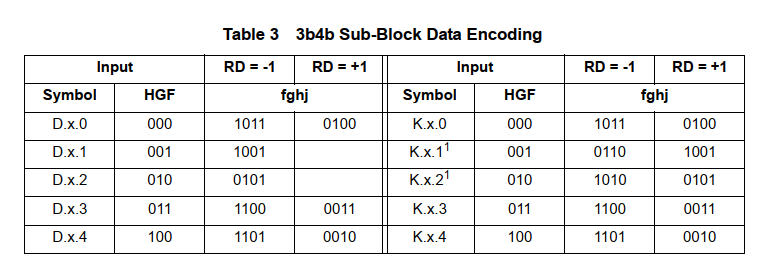
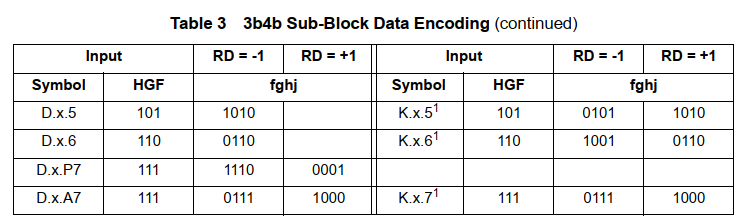
具体使用时,先假设 RD=0, 然后对数据流进行编码。
例如:原始数据0000 0000 ,拆分为 00000 000, 前面5个Bits可以编码为100111,这样 1比0 多2个,RD=+2; 然后计算 000 的编码,因为 RD=+2,所以要选择0多的编码方式,于是 000->0100。 最终结果时 100111 0100 , 可以看到 0 1 数量相同,平衡了。
例如:原始数据 0001 1111,拆分为 00011 111, 前面5个Bits只能编码为110011,0和1一样多RD=0; 然后计算 111 的编码,因为 RD=0,所以可以选择2种,但是选择之后 0 1 仍然不平衡,初始条件变成了 RD=-1或者 RD=+1 ,等待下一个数据进入之后作为初始值继续计算。
K 符号
8位/10位编码器每次编码8位数据,生成10位数据,这意味着编码后的字有1024种可能的组合,而原始字只有256种可能的组合。即使我们假设每个原始字有两种可能的编码字,也只有512种可能的组合。如前所述,有些8位字只有一个对应的10位字,因此10位字的组合少于512种。由此得出结论:至少有512种10位字的组合没有对应的8位字。
因此,8b/10b 编码能够检测物理链路上的比特错误,其原理是检测非法的 10 位字。然而,这种错误检测机制的价值有限,因为它无法检测到所有错误。
8b/10b 编码真正有价值的特性在于 K 符号。K 符号代替8 位字进行编码和传输。解码器能够区分普通数据字和 K 符号,并且始终有方法在收到 K 符号时通知应用程序逻辑。
因此,8b/10b 编码允许发送方在数据通道上发送额外信息,而不会与常规数据混淆。协议通常利用此功能来帮助接收方与发送方的数据流同步。
参考:
- https://www.cnblogs.com/zxdplay/p/19080208 8b/10b 编码的工作原理
- https://zhuanlan.zhihu.com/p/560350350 高速串行通信编码8b/10b(一)
- https://blog.csdn.net/Luckiers/article/details/130470493 8b/10b编码方式(详细)总结附实例快速理解
- https://blog.csdn.net/neufeifatonju/article/details/120548871 详解FPGA实现8b10b编码原理(含VHDL及verilog源码)
- https://www.01signal.com/using-ip/mgt/encodings/ A brief introduction to 8b/10b encoding, 64b/66b, 128b/130b etc.
- https://en.wikipedia.org/wiki/8b/10b_encoding