前面一篇介绍了 ConOut 的换行,然后问题就来了:为什么 Print 的String不需要 \n \r 呢?
这里继续分析:
首先看一下ClsTest.map
0001:0000006d _DebugAssert 000002cd f BaseDebugLibNull:DebugLib.obj
0001:0000006e _DebugAssertEnabled 000002ce f BaseDebugLibNull:DebugLib.obj
0001:00000071 _InternalPrint 000002d1 f UefiLib:UefiLibPrint.obj
0001:000000b1 _Print 00000311 f UefiLib:UefiLibPrint.obj
0001:000000cc _InternalAllocatePool 0000032c f UefiMemoryAllocationLib:MemoryAllocationLib.obj
0001:000000f3 _UnicodeVSPrint 00000353 f BasePrintLib:PrintLib.obj
0001:00000112 _BasePrintLibFillBuffer 00000372 f BasePrintLib:PrintLibInternal.obj
就是说 Print 是来自 UefiLibPrint.Obj,接下来搜索 UefiLibPrint 能找到2个,用实验的方法确定我们需要的是在 \MdePkg\Library\UefiLib\UefiLibPrint.c
INTN
EFIAPI
Print (
IN CONST CHAR16 *Format,
...
)
{
VA_LIST Marker;
UINTN Return;
VA_START (Marker, Format);
Return = InternalPrint (Format, gST->ConOut, Marker);
VA_END (Marker);
return Return;
}
继续追 InternalPrint 发现它调用下面的语句
Return = UnicodeVSPrint (Buffer, BufferSize, Format, Marker);
而这个函数在 \MdePkg\Library\BasePrintLib\PrintLib.c 中
UINTN
EFIAPI
UnicodeVSPrint (
OUT CHAR16 *StartOfBuffer,
IN UINTN BufferSize,
IN CONST CHAR16 *FormatString,
IN VA_LIST Marker
)
{
ASSERT_UNICODE_BUFFER (StartOfBuffer);
ASSERT_UNICODE_BUFFER (FormatString);
return BasePrintLibSPrintMarker ((CHAR8 *)StartOfBuffer, BufferSize >> 1, FORMAT_UNICODE | OUTPUT_UNICODE, (CHAR8 *)FormatString, Marker, NULL);
}
继续追踪 BasePrintLibSPrintMarker 发现他在 \MdePkg\Library\BasePrintLib\PrintLibInternal.c
其中有一个程序段,如下
case '\r':
Format += BytesPerFormatCharacter;
FormatCharacter = ((*Format & 0xff) | (*(Format + 1) << 8)) & FormatMask;
if (FormatCharacter == '\n') {
//
// Translate '\r\n' to '\r\n'
//
ArgumentString = "\r\n";
} else {
//
// Translate '\r' to '\r'
//
ArgumentString = "\r";
Format -= BytesPerFormatCharacter;
}
break;
case '\n':
//
// Translate '\n' to '\r\n' and '\n\r' to '\r\n'
//
ArgumentString = "\r\n";
Format += BytesPerFormatCharacter;
FormatCharacter = ((*Format & 0xff) | (*(Format + 1) << 8)) & FormatMask;
if (FormatCharacter != '\r') {
Format -= BytesPerFormatCharacter;
}
break;
就是说,实际上他在检查字符串是否有 \n 和 \r如果有,那么用 \n \r 替换之(文件中有2处干这个事情的,第一个是在分析 “%”,第二个才是我们想要的)。为了验证,我们将上面这段替换的代码删除,重新编译,运行结果如下:
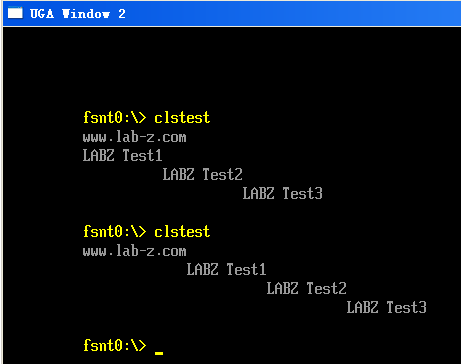
上面一次运行结果是修改之前,下面是修改之后。可以看到,当我们去掉那段自己添加 \n \r做结尾的代码之后,同样会出现只换行不移动到行首的问题。
结论:Print 之所以 \n 直接就能换行移动到行首,是因为他代码中有特殊处理。