EFI 在设计之初就考虑了多语言的支持,使用HII可以轻松的实现汉字的显示。本篇文章介绍获得汉字字形的其他方法,掌握这种方法之后可以在没有HII支持的情况下显示汉字。当然,程序只是为了演示原理,介绍如何读取16×16的汉字字形信息,没有转为图形。
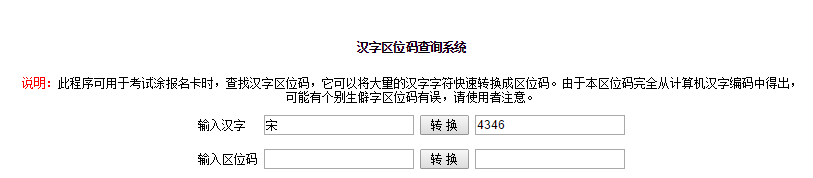
比如:“宋”字查询到的区位码是4346 【参考3】,意思是区码为43,位码是46。计算这个字在字库中的方法是:((43-1)*94+(46-1))*32=6828。之后,在字库文件的 6828偏移处连续读取32个字节即可。
代码如下:
#include <Uefi.h>
#include <Library/UefiLib.h>
#include <Library/ShellCEntryLib.h>
#include <Library/ShellLib.h>
#include <Library/MemoryAllocationLib.h>
extern EFI_BOOT_SERVICES *gBS;
#define FONT_SIZE (16)
#define HZ_INDEX(hz) ((hz[0] - 1) * 94 + (hz[1] -1))*32
#define DOTS_BYTES (FONT_SIZE * FONT_SIZE / 8)
int
EFIAPI
main (
IN int Argc,
IN CHAR16 **Argv
)
{
EFI_FILE_HANDLE FileHandle;
RETURN_STATUS Status;
EFI_FILE_INFO *FileInfo = NULL;
EFI_HANDLE *HandleBuffer=NULL;
UINTN ReadSize;
UINTN i,j;
UINT8 HZChar[2] = {43,46};
CHAR8 *c;
CHAR8 k;
//Open the file given by the parameter
Status = ShellOpenFileByName(L"HZK16K.BIN",
(SHELL_FILE_HANDLE *)&FileHandle,
EFI_FILE_MODE_READ ,
0);
if(Status != RETURN_SUCCESS) {
Print(L"OpenFile failed!\n");
return EFI_SUCCESS;
}
//Get file size
FileInfo = ShellGetFileInfo( (SHELL_FILE_HANDLE)FileHandle);
//Allocate a memory buffer
HandleBuffer = AllocateZeroPool((UINTN) FileInfo-> FileSize);
if (HandleBuffer == NULL) {
return (SHELL_OUT_OF_RESOURCES); }
ReadSize=(UINTN) FileInfo-> FileSize;
//Load the whole file to the buffer
Status = ShellReadFile(FileHandle,&ReadSize,HandleBuffer);
if(Status != RETURN_SUCCESS) {
Print(L"ReadFile failed!\n");
return EFI_SUCCESS;
}
for (i=0;i<DOTS_BYTES;i++)
{
c=((UINT8*)HandleBuffer)+HZ_INDEX(HZChar)+i;
k=*c;
for (j=0;j<8;j++)
{
if (0 == (k & 0x80))
{
Print(L" ");
}
else
{
Print(L"OO");
}
k=k<<1;
}
if ((i+1)%2==0) {Print(L"\n");}
}
FreePool(HandleBuffer);
ShellCloseFile((SHELL_FILE_HANDLE *)&FileHandle);
}
运行结果(特别注意要把字库文件放在Fsnt0:这样的目录下):

更换一下区位码,我们还可以取得“我”的字形。

完整的代码下载:
HZ
最后,关于【参考1】的代码多说两句。其中有unsigned char word[3] = “我”; 这样直接的定义,这是因为很久很久之前,为了编便于 PC处理汉字定义一个汉字由两个大于127的ASCII码组成。组成的规则是:区码+A0,位码+A0。比如,我在中文环境下定义一个“宋”,
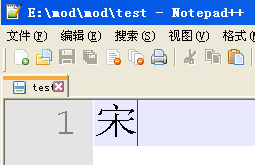
然后切换到英文环境下打开,看到的是2个ASCII码,
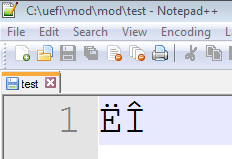
如果再切换到十六进制编辑,会看到 CB CE (前提是保存为 ANSI格式,如果你存为unicode,看到的又是另外的东西)
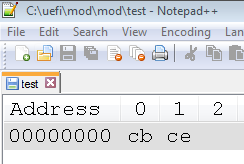
时代已经变了,对于 Windows 编程来说上述的知识都已经过时,如果你需要搞嵌入式开发,还是值得认真学习和理解。
另外,PC刚开始流行的时候,很长一段时间都有汉字不适合PC处理等等的言论,对于普通用户来说,汉字的输入也是很大的困扰。而最终的解决,我认为是人们强烈的交流的需求使得这样的问题很快被克服掉了。时至今日,我仍然能记得同一个寝室的胖子在他的 Nokia手机上,在十几个按键上运指如飞和各种MM聊得火热。很快,没人再认为汉字在PC的普及上是一个问题。
参考 :
1.https://blog.twofei.com/embedded/hzk.html HZK16汉字16*16点阵字库的使用及示例程序
2.http://blog.csdn.net/turingo/article/details/8191712 图灵狗的专栏
3.http://www.jscj.com/index/gb2312.php 汉字区位码查询系统 (具体)
==============================================================
2018年12月30日 补充: 在【参考1】的文章中提供了一个取得字模的代码,我在 Win10 下实验过,很好用:
代码如下:
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
FILE* fphzk = NULL;
int i, j, k, offset;
int flag;
unsigned char buffer[32];
unsigned char word[5];
unsigned char key[8] = {
0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01
};
fphzk = fopen("hzk16", "rb");
if(fphzk == NULL){
fprintf(stderr, "error hzk16\n");
return 1;
}
while(1){
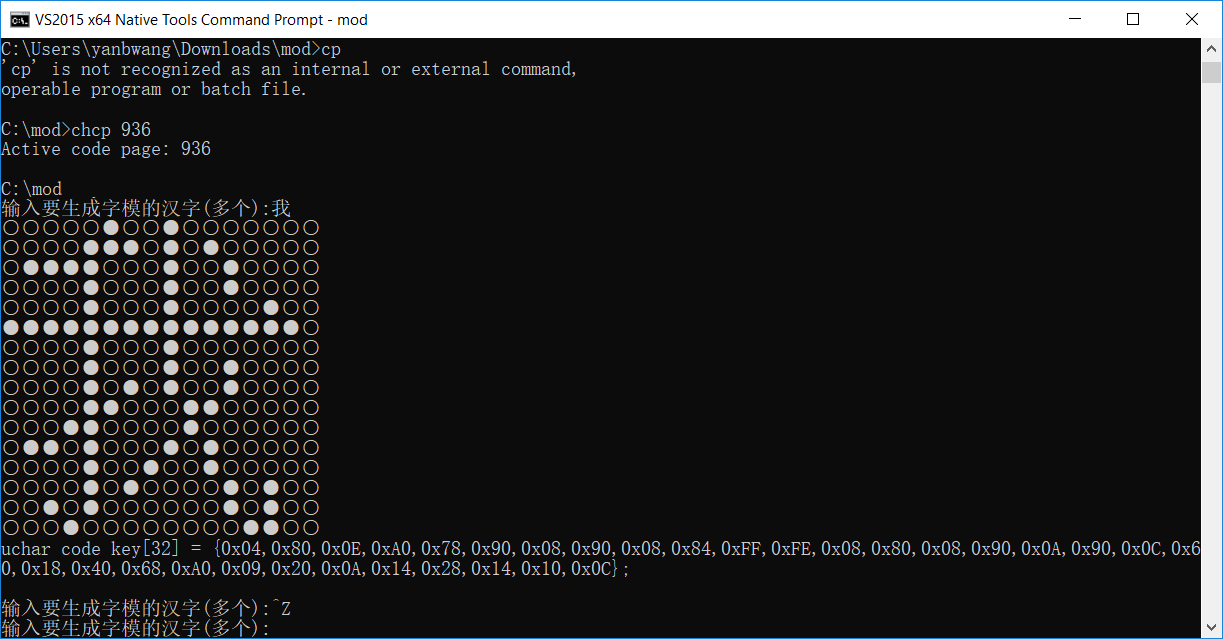
printf("输入要生成字模的汉字(多个):");
for(;;){
fgets((char*)word, 3, stdin);
if(*word == '\n')
break;
offset = (94*(unsigned int)(word[0]-0xa0-1)+(word[1]-0xa0-1))*32;
fseek(fphzk, offset, SEEK_SET);
fread(buffer, 1, 32, fphzk);
for(k=0; k<16; k++){
for(j=0; j<2; j++){
for(i=0; i<8; i++){
flag = buffer[k*2+j]&key[i];
printf("%s", flag?"●":"○");
}
}
printf("\n");
}
printf("uchar code key[32] = {");
for(k=0; k<31; k++){
printf("0x%02X,", buffer[k]);
}
printf("0x%02X};\n", buffer[31]);
printf("\n");
}
}
fclose(fphzk);
fphzk = NULL;
return 0;
}
如果你是英文的OS,需要先切换内码为 CP936